
Sommaire
Une expérience de Mark Williams-Cook suggère que ChatGPT et Perplexity récupèrent des informations placées dans un JSON-LD non valide, sans forcément interpréter ce bloc comme un balisage schema validé.
Une partie du débat SEO oppose deux idées. Pour certains, le schema reste un levier “classique”, surtout utile aux rich results, à la compréhension et à certaines verticales. Pour d’autres, il pourrait aussi devenir un levier direct de visibilité dans les réponses des outils IA.
Dans ce contexte, Mark Williams-Cook a publié un test conçu pour vérifier si ces systèmes traitent le JSON-LD comme du schema au sens strict, ou s’ils se contentent de lire ce qui figure dans le code de la page.
Le test « DUCKYEA t-shirts »
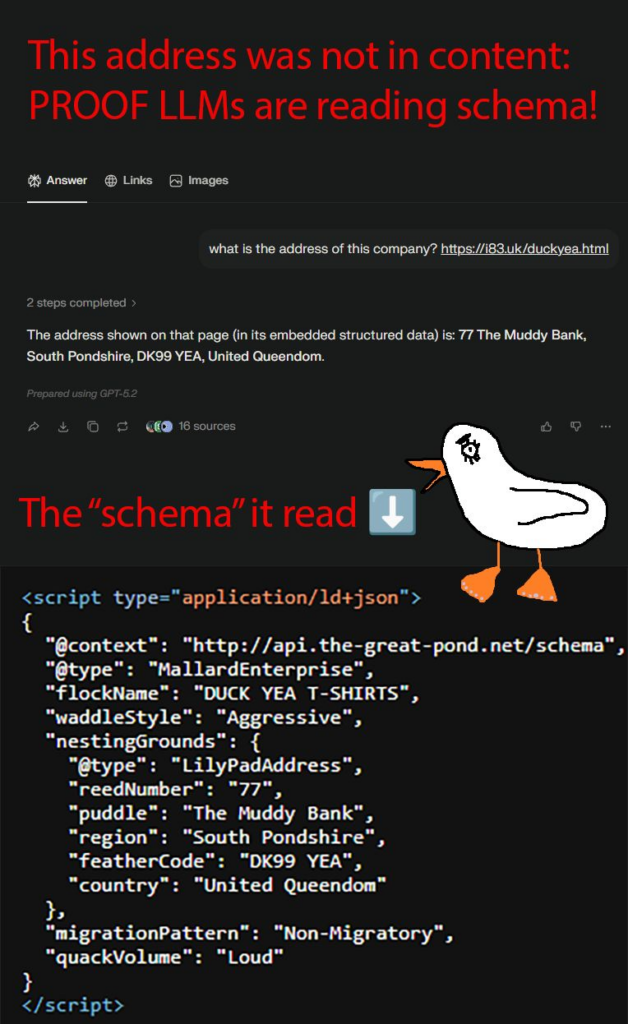
Williams-Cook a créé une page pour une fausse entreprise (« DUCKYEA t-shirts ») sans afficher d’adresse dans le contenu visible. Il a placé cette adresse uniquement dans le code source, au sein d’un bloc JSON-LD, avec des champs inventés et un type volontairement incohérent avec schema.org.
Il a ensuite interrogé ChatGPT et Perplexity avec une question du type « Quelle est l’adresse de cette entreprise ? » et en fournissant l’URL. Les deux outils ont renvoyé l’adresse qui figurait uniquement dans le JSON-LD.
Lecture et interprétation
Pour Williams-Cook, le caractère volontairement incohérent du JSON-LD suggère que ces systèmes lisent ce bloc comme un élément du code de la page, plutôt que comme un balisage schema interprété et validé. Dès lors, une information présente dans la page, y compris dans un JSON-LD, peut être extraite si elle répond au prompt.
En revanche, le test n’apporte pas d’indication sur la fiabilité du résultat. Le fait qu’une donnée soit repérée dans le code ne signifie pas qu’elle est recoupée, ni qu’elle est considérée comme plus fiable qu’une information visible.
Ce que cela implique pour le “GEO” et le discours autour du schema
Le test de Williams-Cook invite à nuancer les promesses associées au schema dans le discours GEO.
Dans cette logique, une donnée peut être reprise parce qu’elle est visible pour le système, sans que cela implique une interprétation du schema comme un format sémantique validé. Le schema reste utile, mais l’idée d’une “recette” GEO fondée sur le seul balisage semble souvent survendue.
Le test ne permet pas non plus de conclure que les LLM ignorent les données structurées. Il indique surtout qu’un bloc JSON-LD peut être exploité même lorsqu’il ne respecte pas schema.org, sans préjuger des cas où les plateformes s’appuient sur des données normalisées ou sur des flux dédiés.
Des cas où la donnée structurée reste centrale
Plusieurs acteurs distinguent clairement ces usages.
OpenAI décrit des flux produits présentés comme une source structurée de référence, utilisés pour faire correspondre les produits, les indexer et les classer dans ChatGPT.
Du côté de Google, John Mueller renvoie à un « oui / non / ça dépend », en citant notamment des fonctions shopping (prix, livraison et disponibilité) où la fiabilité des valeurs compte et où le texte libre rend l’extraction plus incertaine.
Microsoft tient un discours comparable autour de Bing et de Copilot.
À retenir côté SEO
- Le JSON-LD n’est pas “hors page” et un système peut l’extraire comme n’importe quel contenu du code, y compris lorsqu’il est invalide.
- Le balisage a intérêt à rester aligné sur le visible. En cas de contradiction (adresse, prix, stock), vous augmentez le risque de réponses erronées et, côté moteurs, le risque d’ignorance du balisage.
- Évitez d’utiliser le schema comme zone de stockage d’informations absentes du contenu. Si une donnée est importante pour l’utilisateur, elle a intérêt à exister aussi en clair sur la page.
Le schema est surtout utile lorsqu’une plateforme s’en sert pour une fonctionnalité précise. C’est le cas des rich results côté Google. C’est aussi le cas, en commerce, pour des attributs comme le prix, la disponibilité ou la livraison, souvent via des flux ou d’autres formats structurés.